

Customers today expect experiences that are tailored to their preferences, whether in retail, healthcare, energy, or financial services. Meeting these expectations is no small feat: companies must turn vast amounts of historical and real-time data into actionable insights that evolve with changing customer behavior.
Personalization at scale is a complex challenge. It goes beyond traditional segmentation and rule-based recommendations. To succeed, organizations need advanced machine learning (ML) solutions that can handle dynamic human behavior, complex relationships, and diverse data types. In this article, we explore the challenges of personalization, the role of machine learning, and how Amazon Personalize enables companies to deliver hyper-personalized experiences efficiently and at scale.
UNDERSTANDING PERSONALIZATION CHALLENGES
Case studies across various industries demonstrate common personalization problems, including:
- Personalized recommendations
- Finding related items or products
- Personalized search ranking
- Marketing promotions based on customer behavior
Solving these problems often requires dealing with the complexities of the real world:
- Infinite variety of personalities and factors
- Complex non-linear relationships
- Dynamic changes in human behavior
- Natural uncertainty
Traditional rule-based approaches are limited in their capabilities and require incorporating deep subject domain expertise. Instead of manually defining rules, machine learning introduces a bottom-up approach, learning the optimal solution directly from historical data.
Since Netflix held the original Netflix Prize competition in 2009, deep learning has become the de facto state-of-the-art technique for solving personalization problems. Today, it is central to complex recommendation systems at companies like Amazon, Uber, and Spotify.
Despite deep learning's potential to solve any problem supported by data, training an ML solution is an iterative process that involves experimentation and prototyping.
Modern deep learning models, such as Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), require careful tuning and optimization. Navigating their multidimensional hyperparameter and design space is almost impossible without prior ML expertise. Yet, the empirical side of ML development often moves faster than theoretical understanding.
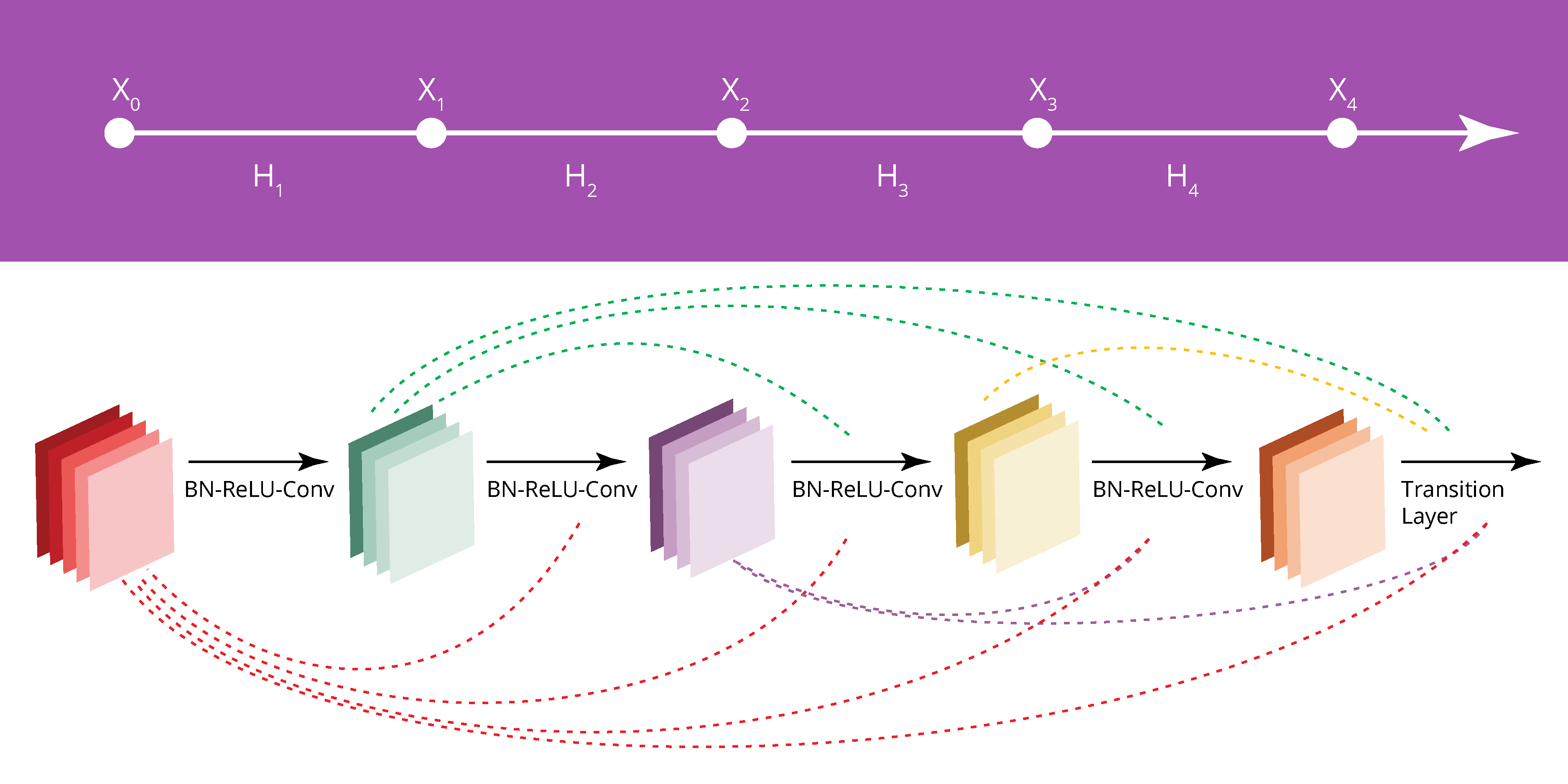
COMPLEXITY OF ML INFRASTRUCTURE AND PRODUCTION
Building in-house ML competency is a significant challenge for enterprises. It involves:
- Establishing data-driven processes
- Hiring rare ML experts from a high-demand talent pool
- Developing workflows that span proof-of-concept experiments to production-grade systems
An ML model lifecycle encompasses much more than just writing ML code. It often consists of multiple stages, workflows, building blocks, and components.
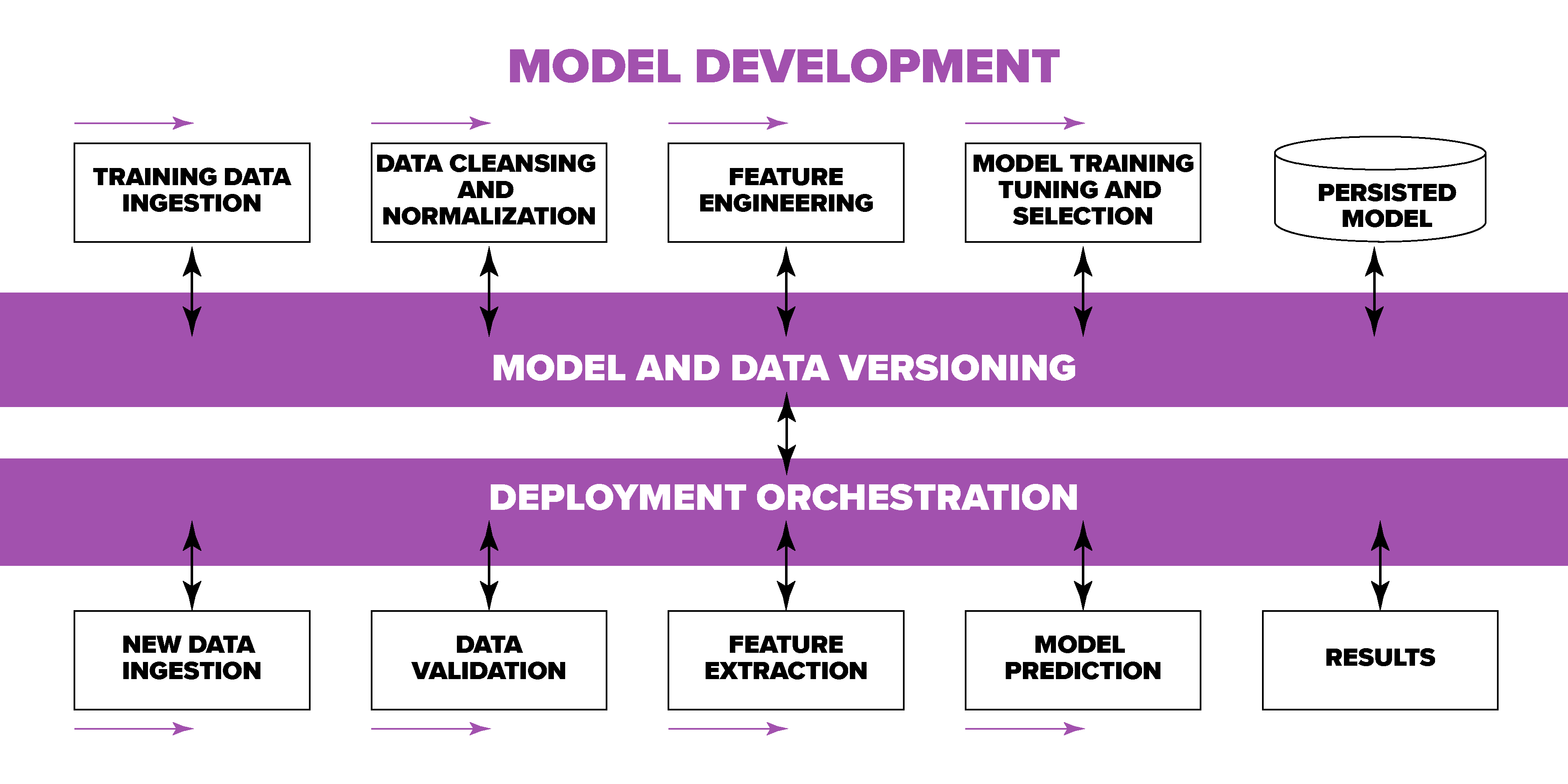
Maintaining ML models in production requires well-established processes and workflows. At the same time, ML introduces fundamentally new challenges for traditional SDLC and CI/CD lifecycles because the system behavior is data-driven:
- ML-specific operations that depend on data (data versioning, feature extraction, model training, evaluation, tuning, and serving)
- A complex landscape of ML tools, libraries, frameworks, platforms, and hardware accelerators
- Large-scale ML workloads involving multiple data sources of different types and ownership
- Dependence on cooperation among multiple teams and stakeholders with varying responsibilities and workflow speeds
- Production deployments requiring constant monitoring, quality control, and the ability to debug and interpret critical issues
These challenges can impact solution performance and significantly increase IT and operational costs if infrastructure or design decisions are suboptimal.
HOW AMAZON PERSONALIZE ADDRESSES THESE CHALLENGES
Amazon Personalize eliminates many of these obstacles by providing a fully-managed ML infrastructure and AutoML capabilities. Organizations can build custom ML recommendation systems with minimal effort, democratizing ML development by using the same technology that powers Amazon.com.
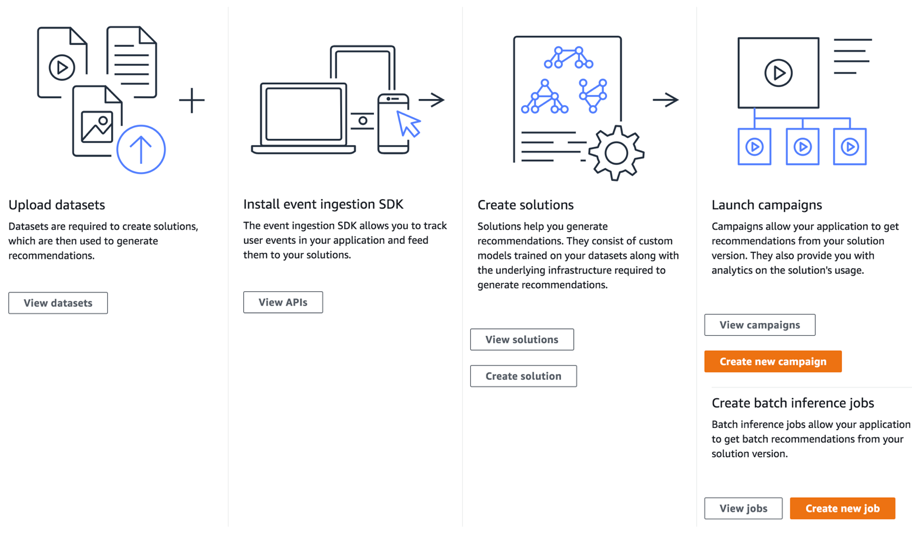
Amazon Personalize offers multiple interfaces for users with varying expertise levels, including:
- Web console
- Command line interface
- Python SDK
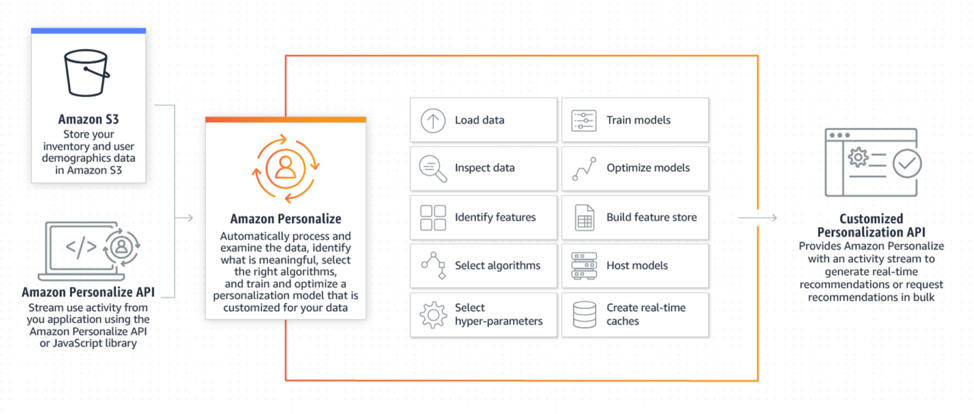
The Amazon Personalize workflow for training, deploying, and serving recommendations consists of:
- Uploading and describing historical training data
- Selecting a model type or letting Amazon Personalize find the optimal solution
- Scheduling training and evaluation jobs
- Analyzing training performance metrics
- Deploying the solution for serving
- Providing recommendations for users
Amazon Personalize can learn from diverse data types, such as:
- Web logs and click streams
- Sales and purchase history
- Transactional data
Minimal data transformation is often required to export data to CSV format.
Predefined Amazon Personalize recipes automate training of complex ML models (like Hierarchical Recurrent Neural Networks) for common personalization use cases. Users can customize recipes or use AutoML to automatically learn optimal parameters through hyperparameter tuning.
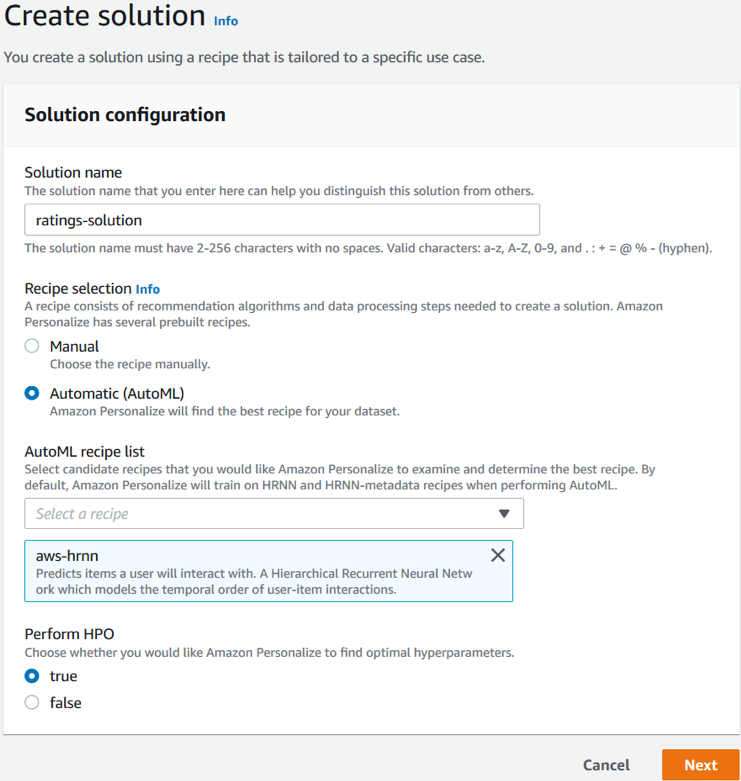
SIMPLIFYING MODEL TRAINING AND DEPLOYMENT
Training an ML model with Amazon Personalize is as simple as clicking a button. The platform handles:
- Underlying infrastructure and resource management
- Job orchestration and data transformations
- Recommendation model training and testing
- Model and data versioning for experiment comparison
Once a model meets target performance metrics, it can be deployed for real-time personalization or batch recommendations. Amazon Personalize provides mature APIs and integration capabilities for most common programming environments, including JS, PHP, Python, Java, .NET, Go, C++, and more.
The platform also captures live events and user interactions, allowing recommendations to be based on both historical data and real-time user sessions. Grouping user experiences by sessions enables more contextual recommendations, continuously improving over time.
WHO BENEFITS FROM AMAZON PERSONALIZE
Amazon Personalize is suitable for:
- Engineering teams, citizen data scientists, and SMEs: deliver personalized experiences without deep ML expertise
- Experienced data scientists: rapid prototyping, experimentation, and validation of initial recommendation solutions or MVPs
- Advanced deployments: can be combined with custom ML models on Amazon SageMaker for ensembles, A/B testing, or multi-armed bandit scenarios, maximizing performance by selecting the best model per user
By providing high-level abstractions such as solutions, campaigns, and events, Amazon Personalize makes ML accessible while still supporting advanced experimentation.
FINAL THOUGHTS
Delivering hyper-personalized experiences is essential to meet modern customer expectations. Amazon Personalize enables companies to:
- Focus on personalized campaigns and experiences rather than ML development
- Iterate quickly from idea to production
- Automate end-to-end ML workflows at scale
- Continuously improve recommendations with new data
- Monitor and debug ML models in production
- Accelerate ML adoption across the organizationAccelerate ML adoption across the organization
Next step: Empower your teams to create personalized, data-driven experiences. SoftServe helps you explore how Amazon Personalize can seamlessly integrate into your workflows and deliver meaningful impact.
Start a conversation with us