

Deep learning models on mobile devices are constrained by smaller memory and less powerful hardware. Overcoming these challenges and providing your users with a better experience requires efficient use of all available resources. In this final installment of our mobile AI blog series, we share how to implement neural networks on mobile devices to complete visual data and computer vision tasks.
Image data loading and preprocessing
To make a model inference with images, they should first be loaded from storage into the RAM and preprocessed (e.g. scaled to the model input size). This can take some time, and it often takes longer than the inference itself. Correct image loading and preprocessing provides the user with a fast response time and avoids application delays.
To address this difference in timing, multithreading can be used as a solution if image preprocessing finishes before inference. Multithreading allows the model to use one thread for inference while images are loaded and processed in another.
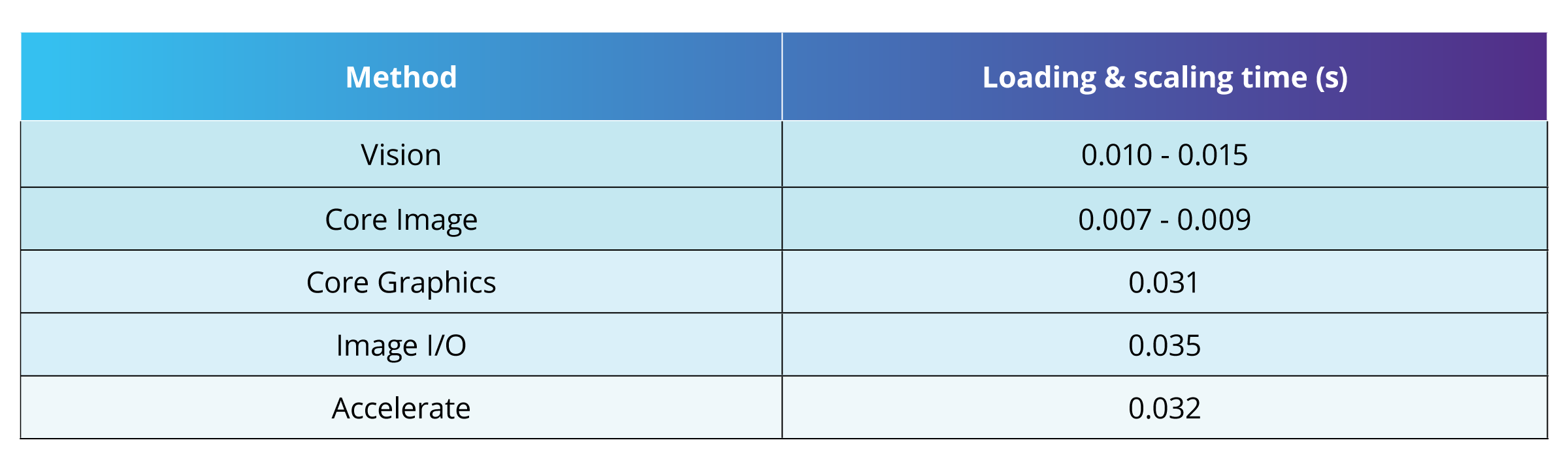
What’s more, it is important to consider how you preprocess the image. Let’s use CoreML as an example. In CoreML, there are several frameworks that allow you to work with the image data, including Core Image, Core Graphics, Image I/O, and Accelerate. In our experience with CoreML, we’ve found Core Image to be the fastest. However, one drawback to Core Image is that it does not always correctly scale the image due to a known bug.
Another option for image preprocessing is the Vision framework, which is specifically designed to work with computer vision algorithms. With Vision, you can easily scale an image and fit it to the model to make an inference. Such inference will take slightly more time since it will include scaling time. This is different from other frameworks where scaling is completed as a separate process before the inference. Even with this delay, Vision performs faster than most of the frameworks for image data loading and preprocessing.
Model pre-initialization
To make a prediction, the inference engine should be initialized and the model should be loaded from memory. It takes additional time to make the first inference--our experience, the first prediction takes from 1.3 to 2 times longer than subsequent predictions. To address this delay, the model can be pre-initialized during the application startup.
Hardware acceleration
Neural network performance depends heavily on the processing unit with which it is executed. It is well known that graphic processing units (GPUs) are more suitable for deep learning models because they can handle small pieces of the data (matrices) in parallel, while central processing units (CPUs) are better to use for the sequential processing of big tasks. All recent iOS devices use CPUs and GPUs, but neural processing units (NPUs) have been available following the launch of iPhone XS.
During development, you can easily set the preferred hardware type in the Swift or the Objective-C code by setting the corresponding parameter while running the model.
However, in our experience, even with an explicit definition of the preferred hardware type the model can be executed on the CPU. There may be two reasons for this:
- According to Apple, during inference, the Core ML inference engine chooses the hardware to run each layer. It is possible that your model runs better on different hardware than the type you specified.
- If the preferred processing unit is overloaded, CoreML may use another hardware type to avoid maxing out a single processor.
- GPU or NPU is not always the best choice for model inference. Since mobile hardware differs from the usual processors used on PCs or in the cloud, it is not guaranteed that the performance boost from the usage of the certain processing unit will be the same. In some cases, it is better to use GPU or CPU, but sometimes all units perform at the same level.

Device overheating
During testing the performance of such CNNs as MobileNetV2, ResNet50, and SqueezeNet1.1 on iPhone X, we noticed that in some cases device was heating up. If ResNet50 was used for a long time, the device heated up and the inference time increased by 10-45%. We assume that is because the ResNet50 is much more computationally expensive than two other models.
We can conclude from this that if the device is continuously heating up, it becomes slower in computations, and that is why it is critical to optimize the neural network inference on the device to provide a great user experience.
Are you ready to take advantage of deep learning models to improve your mobile user experience? LET’S TALK about how SoftServe can save costs and accelerate business operations using the latest artificial intelligence technology.
Don’t miss the previous installments of our mobile AI blog series where we share best practices for deep learning model compression and mobile deep learning frameworks. Also, take a look at our Enterprise Hardware Acceleration demo.