

Field programmable graphics arrays (FPGA) have served as something akin to technological stem cells since 1985, but how do they fare within bleeding edge technology application such as deep learning?
First, a closer look at the current IoT landscape.
Looking at the IoT technology roadmap, we ca n see it is currently in a stage of miniaturization, which involves building energy efficient electronics, software agents, and advanced sensor fusion that allows multiple interconnected objects to behave as a single machine. Computing is shifting to the edge of the IoT network mainly because of data gravity. To make small IoT agents smarter, they need to be able to do more computing, and energy efficiency is a crucial success factor in achieving this.
{kind=link}
Speech recognition, real-time translation, object identification, and emotion recognition are technologies that are now available on smartphones and even smaller devices. The majority of algorithms for this are driven by deep learning, likely due to computation capacities and big data.
“We need more power!”
Artificial intelligence (AI) is rapidly growing as it becomes a new programing paradigm. We approach AI in the forms of machine learning (ML) and, in particular, deep learning. Modern ML achievements are possible due to data and computing power that were not available ten years ago. The need for greater computing power is growing faster than the computing capacity of general-purpose hardware.
FPGA vs. GPU in an AWS showdown
We measured performance per dollar of GPU and FPGA hardware using Amazon AWS EC2 instances.
The test benchmark is based on Caffe ImageNet image classification using six award-winning neural network architectures (AlexNet, GoogleNet, CaffeNet, NIN, Vgg16, Vgg19). This test bench is based on an AMI Deep Learning Zebra Deep-Learning engine for Caffe (1 FPGA) by Mipsology.
For the benchmark, unmodified DNN and Caffe were used (based on float64). It is expected that with lower-precision and sparse DNN could dramatically change the results towards better results for FPGA.
As an FPGA inst ance we used f1.2xlarge as the comparable instance type to GPU p2. The F1 instance is based on Xilinx UltraScale+ VU9 on AWS, cost is $1.65 per Hour.
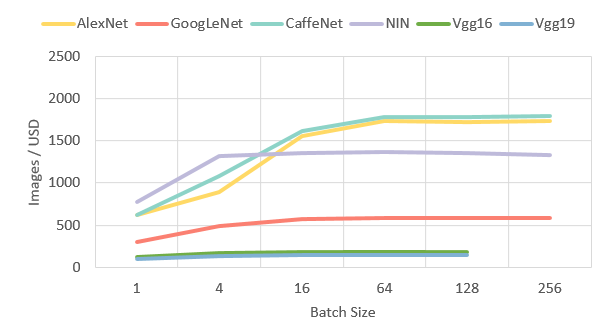
1 Comparative performance, Images / USD, batch = 64
This benchmark experiment is the first step to better understanding the performance of hardware AI accelerators on typical ML tasks. We plan to measure performance per watt, per volume, and per mass with real Xilinx and Altera FPGA chips as soon as they arrive.
Stay tuned for more updates from our R&D lab!