

Machine learning (ML) is transforming oil and gas (O&G) exploration by taking over repetitive, error-prone, and low-value tasks. This speeds up seismic interpretation and allows geophysicists to focus on higher-value work.
Despite these clear benefits, seismic surveys and data processing have been slow to adopt ML. Traditional methods still dominate, leaving much of the potential for efficiency and accuracy untapped.
Today, geoscientists spend large amounts of time collecting, sorting, and preparing seismic data. By applying ML to upstream operations, companies can reduce operating costs by 2–5%. Since a failed exploration can cost $5–20 million with no chance of recovering the investment, ML can save millions on unsuccessful projects and add millions in value to successful ones.
In this article, we explore why modernization is critical, the key challenges in seismic data processing, and a step-by-step solution SoftServe recommends based on our experience building and deploying ML-powered seismic tools.
Overcoming Challenges in Seismic Data Processing
Seismic data processing is complex and resource-intensive. Machine learning, combined with other advanced technologies, helps overcome the most common challenges, including:
- Processing and reusing massive volumes of data efficiently for future analysis
- Improving data quality by removing noise and filling in gaps with ML-generated predictions
- Detecting geological features such as horizons, channels, and faults
- Matching new seismic surveys with existing datasets for more versatile exploration and cross-analysis
SoftServe has designed a user-focused, full-cycle solution for seismic data processing. It enables users to:
- Upload seismic files to a secure data lake
- Access processed data through an intuitive web interface or integrations with third-party tools
- Explore detailed seismic models that reveal sub-surface structures, depositional layers, and erosional features, including faults, channels, horizons, and salt bodies
Architecture of an Ml-powered Seismic Solution
The architecture of an ML-powered seismic solution involves several key steps. Below, we break down the process from raw file upload to real-time access of fully processed seismic models.
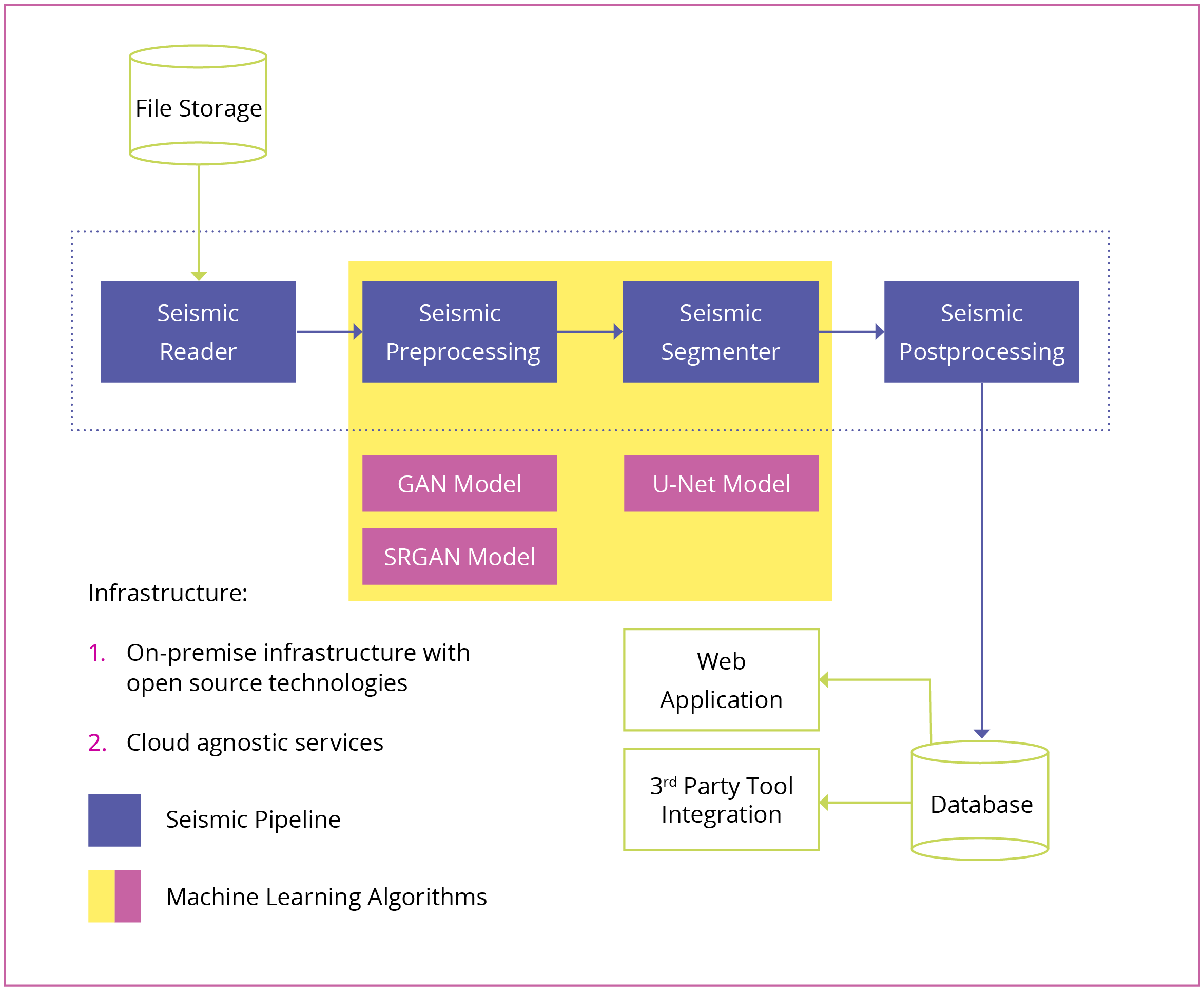
Step 1: Load SEG-Y files into storage
The process begins when a user uploads SEG-Y files into file storage. As soon as the files are loaded, the system automatically starts processing.
Storage can be on-premises or in the cloud. Cloud storage is recommended because it provides:
- Unlimited storage space
- Ability to handle files of any size
- File redundancy to prevent data loss
- Flexible access controls
- Encryption for data and communication
- Lower upfront costs
- Greater scalability and flexibility
SEG-Y files act as data cubes, storing seismic traces from the surface deep into the earth. They also contain metadata with essential details such as coordinates, company and client information, recording date and time, and trace header schemas.
Step 2: Parse file headers
The system then extracts critical information from the file headers, typically the xline and inline trace positions.
In some cases, seismic files are incomplete or corrupted, which means this information may be missing or stored in an unexpected format. A machine learning algorithm analyzes both the file headers and trace data to intelligently detect the correct byte positions.
Step 3: Read trace data
Once the inline and xline positions are identified, all traces can be read to construct the seismic data cube.
Key points to note:
- File sizes can reach 1 TB or more
- Traces are read one at a time, so the entire file doesn’t need to be loaded into RAM
- Reading can be done in parallel across clusters, which speeds up processing and lowers costs
- Cloud-based ML services allow data scientists and engineers to move models from idea to production quickly and efficiently
Step 4: Remove noise from data
Noise is inevitable in seismic data due to environmental and operational factors. Examples include:
- Random noise: wave action in marine environments, wind, vehicle traffic in land environments, electronic instrument noise, cable vibrations, and nearby drilling operations.
- Coherent noise: undesirable seismic energy that shows consistent phase from trace to trace, such as acquisition footprints, shallow refractions, and multiples.
- Signal decay: occurs under certain geological conditions, e.g., under salt deposits, which are key indicators for oil or gas reservoirs.

Noise reduces data quality, making surveys less informative. To address this, our solution leverages Super-Resolution Generative Adversarial Network (SRGAN), a deep learning neural network model that restores high-resolution images from low-resolution files.
Two-step process:
- Remove high frequencies from seismic data
- Use SRGAN to recreate all parts without noise

This produces significantly improved detail and quality for interpretation.


Bottom image. Same data after noise filtering
Step 5: Fill gaps with data in-painting
Missing sections of seismic data are common due to acquisition limits. To resolve this, our solution applies a Generative Adversarial Network (GAN).
- The generator predicts new data based on patterns in the dataset
- The discriminator evaluates whether the data looks real or generated
- Through multiple iterations, the generator improves until the discriminator can no longer tell the difference
This technique fills gaps and restores incomplete sections of seismic surveys. Inspired by NVIDIA’s work with GANs in graphics, SoftServe applies the same approach to seismic data, improving completeness and reliability.

Step 6: Predict horizons, channels, and faults
After improving data quality, ML algorithms detect horizons, channels, and faults using a 3D U-net neural network:
- U-net is a convolutional network architecture for fast and precise segmentation of images
- Input: seismic surveys
- Output: masks with probabilities used to detect horizons, channels, and faults in the seismic data
This step improves geophysical interpretation and supports more accurate exploration and drilling decisions.
Step 7: Post-process results
Once processing is complete, preview images of the seismic cube are generated for quick display in a web interface.
Additional data, such as well locations and well logs, can also be cross-referenced with seismic surveys, enabling geophysicists and petroleum engineers to make more informed decisions.
Step 8: Save results for real-time access
Finally, the processed seismic results are stored in the cloud for real-time access through a web interface or existing industry tools such as Petrel or Seisware.
Benefits of Modernization
Automating seismic data processing with ML provides several benefits:
- Significant reduction in processing time
- Fewer errors and less human bias
- Cost savings through more efficient operations
- Access to large-scale, high-quality seismic datasets
- More accurate decision-making for exploration and production
The ML-driven solution automates:
- Noise detection and removal
- Horizon, channel, and fault prediction
- Data gap filling
Conclusion
Manual seismic data processing is no longer sustainable when ML, cloud computing, and advanced technologies are available. Delaying modernization slows workflows and increases exploration costs.
SoftServe has developed a cloud-agnostic, ML-powered seismic solution that can be customized for any platform. Beyond processing, future applications include advanced modeling and reservoir parameter prediction, helping optimize exploration and production strategies.
Where are you in your seismic data processing journey? Contact SoftServe today to discuss first steps toward saving time and money in oil and gas exploration.
Start a conversation with us