

Bridge Simulation and Reality Through Next-Generation Virtual Gyms
In brief
- Modern factories demand adaptable robotic systems.
- Reinforcement learning trains robots through experience, not rigid models.
- High-fidelity virtual gyms reduce the simulation-to-reality gap.
- A five-stage workflow ensures safe deployment and continuous improvement.
Robots have long excelled at repeatable, highly structured tasks. Yet modern production environments demand far more. They vary, drift, shift, and introduce new products and conditions without warning. Traditional control approaches struggle under such variability because they rely on rigid mathematical models or time-consuming manual tuning. When the real world diverges even slightly from the expected one, performance quickly degrades.
Recent advances in learning-based control, especially reinforcement learning (RL), have expanded what robots can learn to do. Instead of deriving policies analytically, robots learn behaviors through experience. But this shift also creates new challenges. RL requires massive amounts of data, which cannot safely be collected on real hardware, and even sophisticated simulators often fail to capture the subtle physical effects that shape real-world performance. This mismatch between virtual training and physical deployment is known as the simulation-to-reality gap.
High-fidelity matters
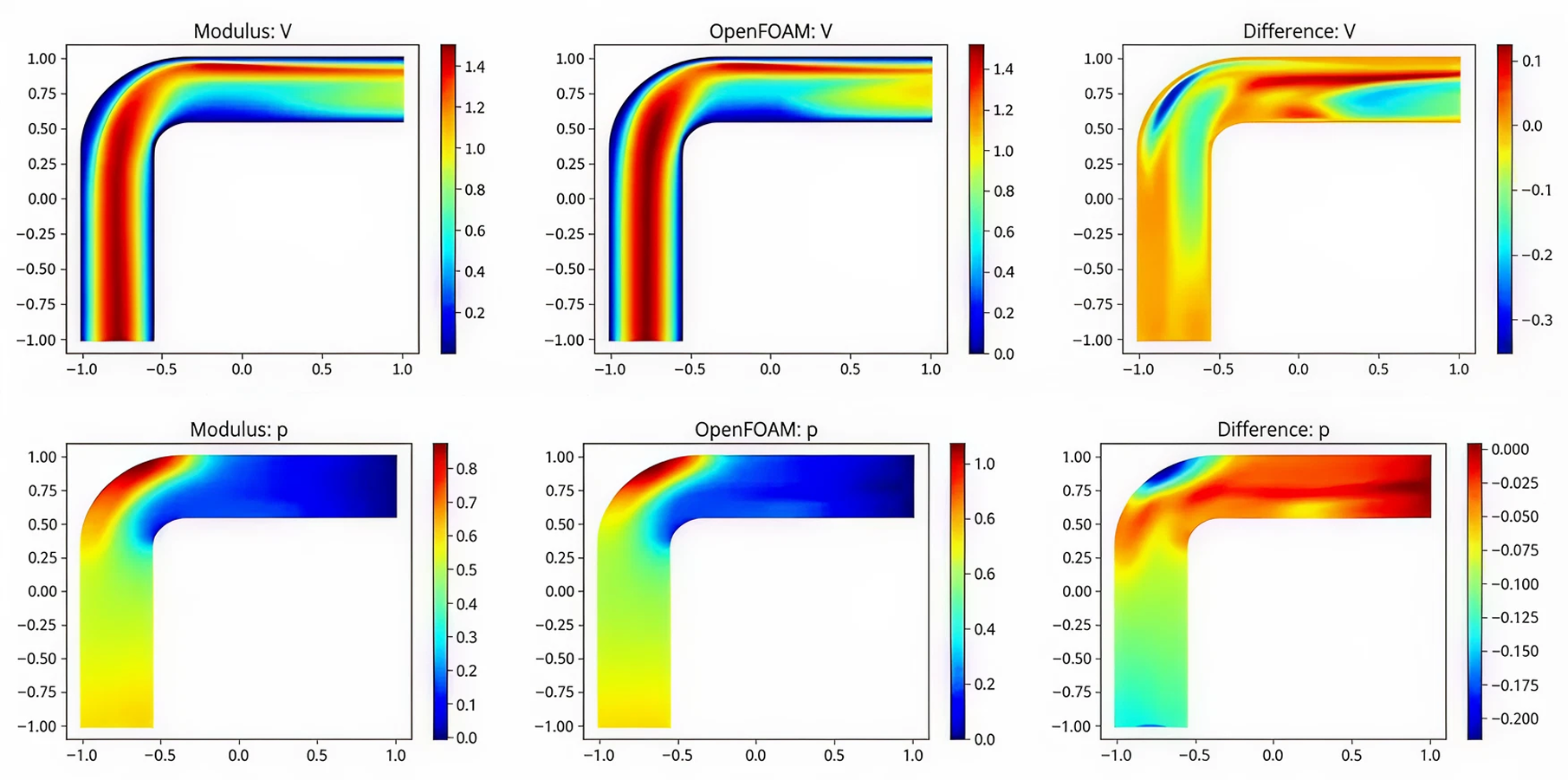
Many real-world failures originate in nuances that low-fidelity simulators cannot capture, such as material deformation, contact instability, friction variation, or multi-physics interactions. High-fidelity world models allow robots to train on these phenomena before encountering them on the factory floor. Hybrid simulation approaches combine first-principles physics with data-driven residual models to represent complex effects more accurately, while co-simulation frameworks integrate specialized solvers into unified environments.
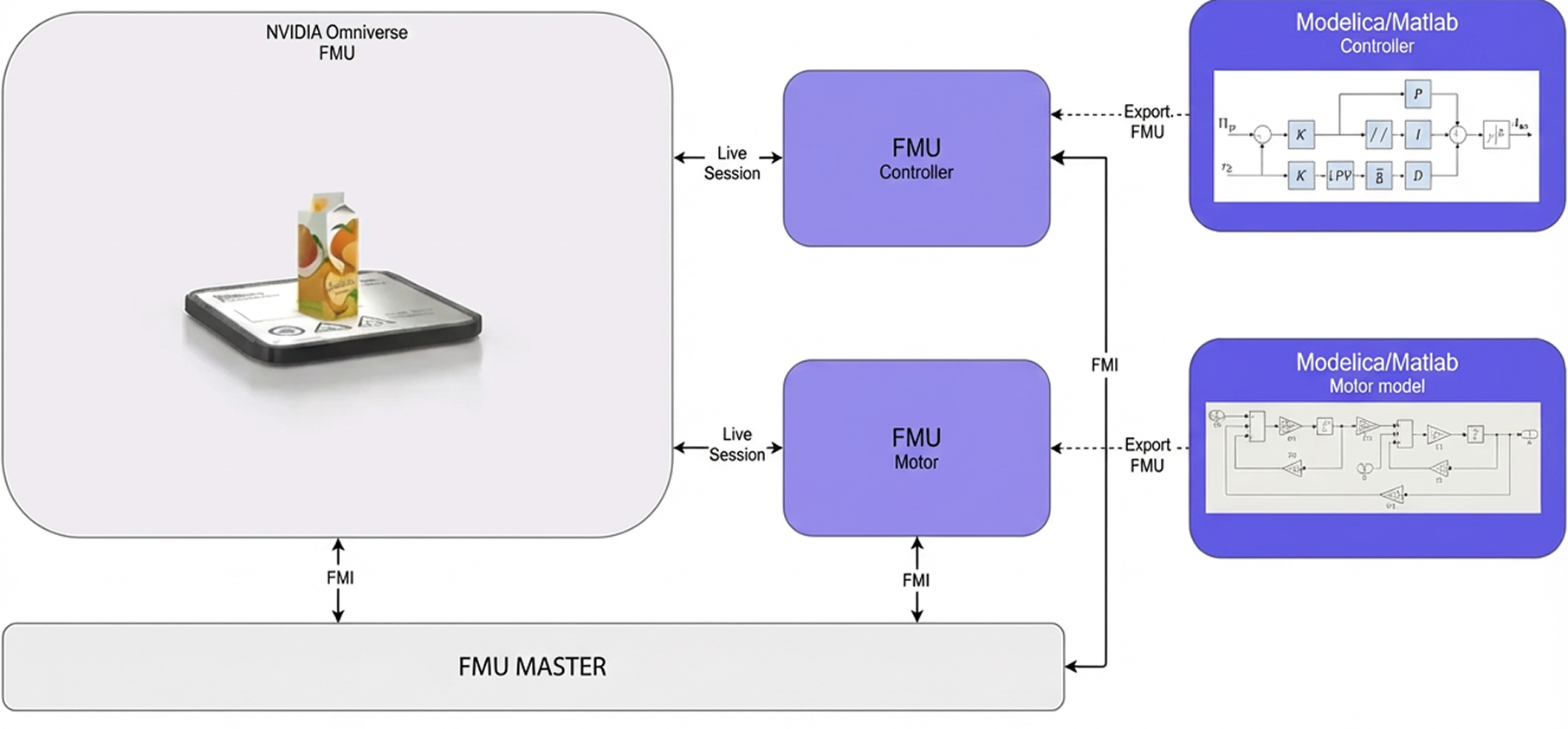
To further improve learning efficiency, differentiable world models allow gradients to propagate through the environment itself. This moves training away from random exploration and toward analytical optimization, accelerating convergence and reducing the need for extensive physical fine-tuning. Surrogate models, such as neural ordinary differential equations (NODEs), physics-informed neural networks (PINNs), and reduced-order models, supplement these simulations when full-scale physics is computationally expensive.
Together, these components form high-fidelity virtual gyms where robots train at scale under realistic and varied conditions, improving robustness and preparing for deployment.
A production-ready pathway from simulation to deployment
Virtual training alone is not enough. Success depends on a workflow that maintains alignment between the digital and physical domains throughout the lifecycle of a robotic system. An effective production-ready workflow includes five stages:
1. Assess high-variance, high-value tasks such as complex picking, weld-seam tracking, or inspection, and define clear performance metrics.
2. Model the work cell with accurate CAD, sensor layouts, and material properties to build a realistic digital twin inside the virtual gym.
3. Train policies across parallel simulations using curriculum-based RL with safety constraints applied from the start.
4. Validate through hardware-in-the-loop testing, comparing real telemetry with simulated predictions.
5. Deploy containerized policies to edge devices and refine them through over-the-air updates as new data is collected.
This pipeline creates a low-risk, high-traceability method for transitioning from simulated learning to reliable physical autonomy.

Real business impact
Organizations adopting this approach see benefits across engineering, production, and safety. They see advantages in the form of:






SoftServe’s unique value
SoftServe delivers end-to-end enablement for physical AI, providing:
- High-fidelity virtual gyms tailored to each client’s work cell and requirements
- Selection and training of AI-based surrogate models for efficient, physics-aligned simulation
- Scalable training pipelines for RL-based policies in realistic virtual environments
- Fine-tuning on real systems to close the simulation-to-reality gap and ensure stable deployment
Through this integrated offering, organizations can move confidently from experimental prototypes to production-grade autonomy.
