

Apache Kafka is a distributed, fault-tolerant, open-source streaming platform designed to process massive volumes of data in real time. It enables organizations to handle data streams efficiently and build systems that react instantly to new information.
However, Kafka can be complex to configure and manage. A standard production setup requires multiple components, such as ZooKeeper, Kafka Broker, and Schema Registry, deployed across several servers to ensure fault tolerance. Updates must also be done manually and carefully to maintain compatibility between brokers and clients.
Confluent Cloud is a simpler alternative. Confluent Cloud provides a fully managed Kafka service, allowing you to spin up a production-ready Kafka cluster in minutes instead of hours. It supports Kafka Streams and KSQL, and can be deployed on major cloud platforms, including Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure.
To explore how Confluent Cloud performs in practice, we built a small, real-world data pipeline to tackle an engaging problem: estimating public sentiment toward Brexit. In other words, we aimed to calculate a Community Approval Rating (CAP), a score showing how positively or negatively people talk about Brexit online. Let’s see how it works.
Implementation
We chose Twitter as our data source because it is an open platform where people freely express opinions. Using Twitter allowed us to collect a broad, relatively unbiased sample of public posts. Kafka is used to store tweets and intermediate results reliably and to decouple the different stages of the pipeline. Each step can run independently and communicate via Kafka topics.
The first practical step was getting a Kafka cluster running. With Confluent Cloud, this is straightforward: you log in, request a cluster, and provide a few details (cluster name, cloud provider, and region). For anyone familiar with manually configuring Kafka, the managed experience may feel almost too simple. You request a cluster, and a production-ready environment appears, with configuration and updates handled by the service.
Confluent Cloud also lets you choose the cloud provider for the cluster. We co-locate processing components with the Kafka brokers to reduce latency and lower inter-region traffic costs. In our workshop, we used GCP, but the same setup works on AWS or Azure.
The pipeline consists of four main steps:
- Retrieve tweets
- Analyze sentiment
- Calculate CAR
- Serve the score via an HTTP endpoint
Below, we describe each step in detail.
All pipeline components are written in Python and use the confluent_kafka client (Confluent’s open-source Python library) for producing and consuming messages. We use Avro for message serialization to ensure efficient, schema-based transport and storage within Kafka. All components are hosted on GCP.
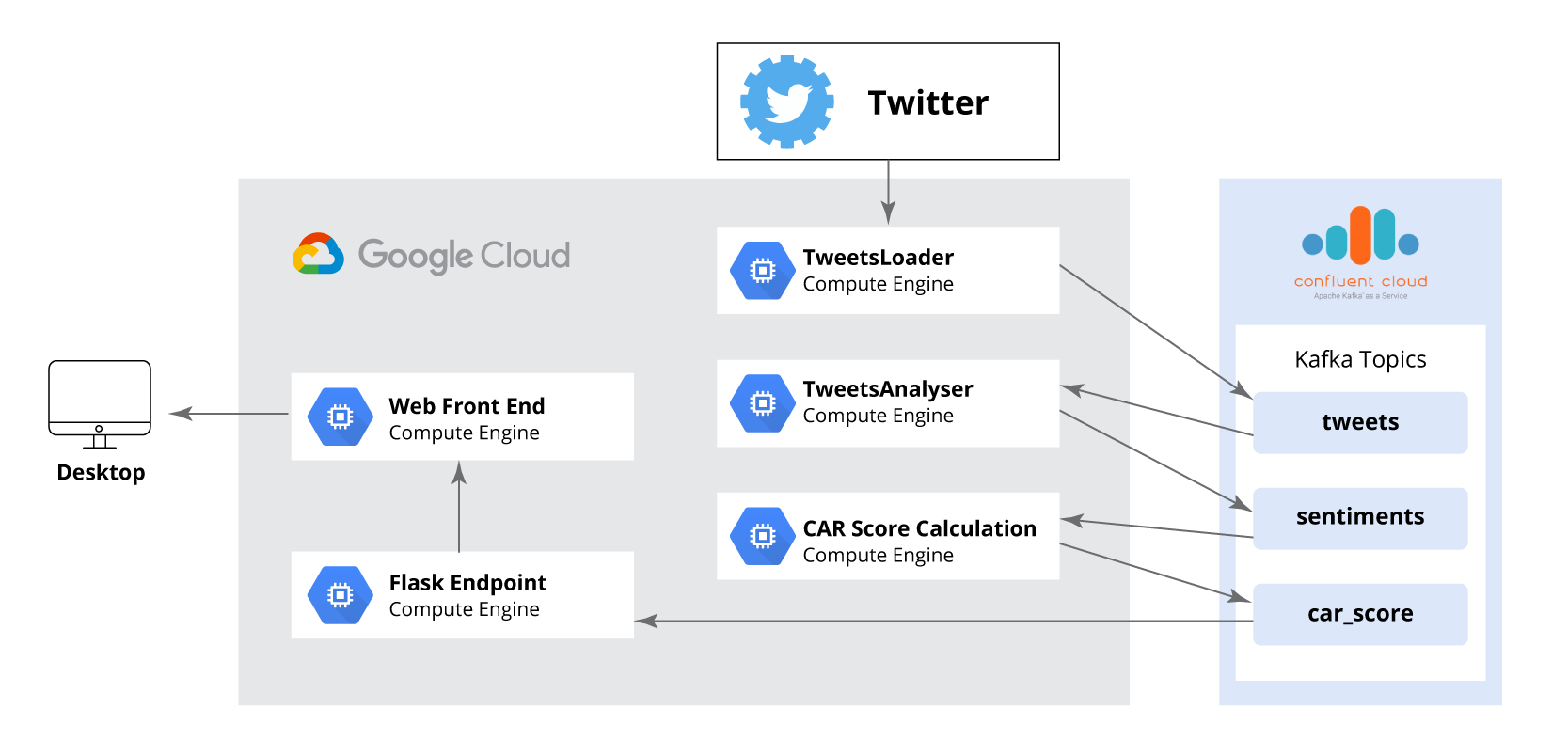
Step 1: Retrieve tweets
The first step is to collect tweets through the Twitter API and save them in a Kafka topic called tweets.
Although Twitter offers a Streaming API that delivers tweets in real time, we chose not to use it for two main reasons:
- We also needed access to historical tweets. Relying only on new tweets would exclude a large portion of valuable data.
- The Streaming API works in a user context and requires user authorization, which doesn’t fit our use case since our service doesn’t interact with Twitter users directly.
Instead, we developed a Python service called TweetsLoader. It uses the Twitter API to first gather all available historical tweets and then continuously pull new ones. This way, the rest of the system processes both old and new tweets the same way.
Because the Twitter API limits the number of allowed requests, we implemented mechanisms to balance retrieval speed with rate-limit constraints, ensuring stable and continuous data collection without interruptions.
Step 2: Sentiment analysis
This stage can vary in complexity depending on the chosen approach. To get the pipeline running quickly, we started with a simple, ready-to-use solution. One of the advantages of Kafka-based pipelines is that each step is independent, so it’s easy to replace this part with a more advanced model later.
For sentiment analysis, we used the TextBlob Python library. It requires minimal setup and delivers reasonable accuracy for basic tasks. TextBlob is built on top of NLTK, a standard toolkit for natural language processing in Python.
This step consumes tweets from the tweets Kafka topic, processes each one, and assigns a sentiment score. TextBlob outputs a numeric value between –1.0 and 1.0, where –1.0 represents a strongly negative sentiment, 1.0 a strongly positive one, and 0.0 a neutral tone. The results are then written to a separate Kafka topic called sentiments.
Step 3: CAR score calculation
The CAR score represents the average sentiment across all collected tweets. In this step, the system reads sentiment values from the sentiments Kafka topic and computes the average score along with the total number of analyzed tweets — positive, negative, and neutral.
The results are written to a Kafka topic called car_score. To keep the user interface responsive, the calculation runs after every 100 messages rather than waiting for the entire dataset to be processed. This ensures the score is updated frequently and displayed with minimal delay.
The car_score topic is deliberately set up with a single partition to maintain message order. Since we only need the most recent CAR score, this configuration ensures that the last message in the topic always reflects the latest calculated value. Kafka preserves message order within a partition, which makes this approach both simple and reliable.
Step 4: Serve the score
The final step in our pipeline is serving the calculated CAR score to users. This component is implemented as a Python Flask application that retrieves the latest message from the car_score Kafka topic whenever a request is made. It then returns the most recent sentiment score to the client.
Since our team primarily focuses on big data engineering, we built a simple front-end interface to visualize the results, while a dedicated design team at SoftServe typically handles the UI for production-grade projects. The interface regularly queries the Flask backend and refreshes the score in real time as new tweets are analyzed.
CONCLUSION
The full project, including all code and configuration, is available on GitHub (MIT License).
In this workshop, we used Confluent Cloud to quickly set up a data pipeline consisting of three Kafka topics, three Python processing steps using the confluent_kafka package, and a Flask backend application. Publicly available tweets served as our data source, which we stored reliably in Kafka. Confluent Cloud simplified the setup and configuration, allowing us to focus on building the application itself rather than managing infrastructure.
This case demonstrates that meaningful insights from large, unstructured data can be generated in a single day when the right tools are used. With Apache Kafka, Confluent Cloud, and GCP, the amount of code required is minimal, and results can be obtained quickly.
At SoftServe, we combine deep technical expertise and practical experience to help organizations design and implement scalable data solutions like this.
Start a conversation with us