

SoftServe Document Intelligence with Databricks Genie: Overcoming RAG Limitations

In brief
- Traditional RAG systems fall short in enterprise environments that require accuracy, consistency, and governance.
- SoftServe's Document Intelligence with Databricks Genie adopts a Structure-Augmented Generation (SAG) approach, transforming unstructured documents into structured, validated data.
- The solution leverages Databricks native AI functions and next-generation Genie to deliver a unified, conversational document intelligence platform.
What’s Wrong with Traditional RAG?
Large Language Model (LLM)-powered chatbots have rapidly become the default interface for interacting with enterprise knowledge. Organizations increasingly rely on conversational assistants to answer questions over vast collections of unstructured data stored in systems such as SharePoint, Google Drive, and other corporate repositories. From contracts and invoices to reports and emails, these documents contain critical business information. However, unlocking that value in a reliable way remains a challenge.
The most common architectural pattern powering these experiences is Retrieval-Augmented Generation (RAG). In a typical RAG setup, relevant document fragments are retrieved using semantic search and passed to an LLM to generate a response. While this approach is effective for many general-purpose use cases, its limitations become evident in enterprise environments where accuracy, consistency, and governance are non-negotiable.
Several key challenges emerge with RAG-based systems:
These limitations are not just technical inconveniences; they directly impact business trust in AI systems. When decisions depend on document-derived insights, organizations need more than plausible answers; they need verifiable, structured, and governed outputs.
Instead of relying solely on raw text retrieval and interpretation, SAG introduces a preprocessing layer that transforms unstructured documents into structured, validated data. This structured representation becomes the foundation for downstream querying, analytics, and reasoning. LLMs are still used, but their role shifts from interpreting raw documents to interacting with curated, high-quality data.
The benefits are significant:
- Deterministic outputs through schema-driven extraction
- Improved accuracy by grounding responses in structured data
- Support for analytics and aggregation using queryable datasets
- Enhanced governance and traceability with clear data lineage
Historically, implementing SAG required assembling a complex ecosystem of components: OCR engines for document parsing, machine learning models for classification and extraction, text-to-SQL systems for querying structured data, RAG pipelines for semantic retrieval, and orchestration layers to combine these capabilities into a cohesive solution. This resulted in high implementation costs, operational complexity, and fragmented architectures.
Recent advancements in Databricks significantly simplify this landscape. With the introduction of native AI functions for document processing and the next generation of Databricks Genie, now capable of interacting with both structured and unstructured data sources, organizations can now implement SAG patterns within a unified platform.
By combining automated document processing, structured data modeling, and natural language interaction, this solution enables enterprises to move beyond the limitations of RAG and toward a more reliable and actionable AI-driven data experience.
SoftServe Document Intelligence with Genie
At the core of SoftServe’s approach is a cohesive, end-to-end pipeline that transforms raw enterprise documents into structured, queryable intelligence and makes it accessible through a conversational interface powered by Databricks Genie.
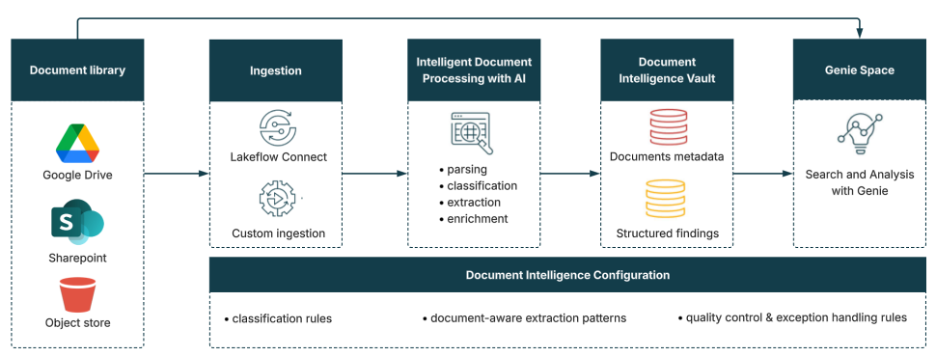
End-to-End Data Processing Flow
The solution begins with a data ingestion layer that accesses documents from enterprise content management systems, such as SharePoint or Google Drive. This can be implemented using native Databricks connectors or custom-built ETL pipelines, depending on the organization’s architecture and security requirements. The ingestion process supports incremental updates, ensuring that newly added or modified documents are continuously incorporated into the pipeline.
Once ingested, documents enter the parsing stage, where unstructured content is prepared for downstream analysis. This step leverages Databricks’ ai_parse function to extract text and preserve relevant structural elements from a variety of document formats, including PDFs, scanned files, and office documents. The goal is to convert raw binary content into a normalized representation that can be processed consistently at scale.
Following parsing, the solution applies document classification using the ai_classify function. Classification plays a critical role in determining how each document should be processed. For example, invoices, contracts, and claims documents each require different extraction logic and schemas. By accurately identifying document types, the system can route them through the appropriate processing pathways.
The next stage involves information extraction, where the ai_extract function captures structured data elements specific to each document type. These may include key fields, such as invoice totals, contract dates, customer information, or policy details. Extraction is guided by predefined schemas to ensure consistency and reliability across documents.
The outputs of classification and extraction, along with document metadata, are then consolidated into a centralized repository known as the Document Intelligence Vault. This vault serves as a curated, structured storage layer built on Delta Lake, providing a single source of truth for all processed document data. It enables efficient querying, supports data governance, and ensures that extracted information is readily available for downstream applications.
Configurable Intelligence: Classifiers and Extraction Rules
A defining feature of SoftServe’s solution is its emphasis on configurable intelligence components.
Rather than relying on static, hard-coded logic, the system uses customizable classifiers and extraction rules defined during the solution setup phase. These configurations are stored in Delta Lake and act as the control layer for document processing.
Classifiers define how documents are categorized, including hierarchical taxonomies and confidence thresholds. Extraction rules specify the schemas and logic used to capture structured data from each document type. Together, these components enable:
- Flexibility: allowing the system to adapt to different business domains and document formats.
- Reusability: supporting consistent processing across multiple use cases.
- Governance: with version-controlled configurations that can be audited and updated over time.
Conversational Access with Databricks Genie
Once documents have been processed and structured, data is available in the Document Intelligence Vault, where the final layer of the solution focuses on data consumption and interaction.
Both the structured data in the vault and the original source documents in SharePoint or Google Drive are made accessible to the next-generation Databricks Genie environment. Genie provides a conversational interface that lets users interact with data in natural language, whether through a web browser or a mobile device.
- This integration enables a wide range of capabilities:
- Querying structured data using natural language, without requiring SQL expertise
- Combining structured insights with contextual information from source documents
- Exploring relationships and trends across large document collections
- For example, a business user can ask questions like:
- “What is the total value of invoices processed last quarter by the vendor?”
- “Which contracts are expiring in the next 60 days?”
- “Summarize key obligations in our active agreements.”
Behind the scenes, Genie translates these queries into appropriate operations, leveraging structured data where possible and augmenting responses with contextual information from unstructured sources when needed.
In addition to direct user interaction, Genie can also be integrated into broader enterprise ecosystems through its conversational API. This allows organizations to embed document intelligence capabilities into agentic workflows, customer-facing applications, or internal automation tools.
Conclusion
As organizations continue to invest in AI-driven solutions, the limitations of traditional RAG-based approaches are becoming increasingly apparent. While RAG provides a useful foundation for interacting with unstructured data, it falls short in scenarios that require accuracy, consistency, and enterprise-grade governance.
SoftServe’s Document Intelligence with Databricks Genie addresses these challenges by adopting a Structure-Augmented Generation approach, transforming unstructured documents into structured, validated data and enabling reliable, conversational access to that information.
By leveraging recent advancements in Databricks, including native AI functions and the next generation of Genie, this solution eliminates the need for fragmented architectures and complex integrations. Instead, it provides a unified platform that seamlessly integrates document processing, data management, and user interaction.
The result is a powerful, scalable solution that not only overcomes the limitations of RAG but also unlocks new possibilities for enterprise intelligence. Organizations can move beyond simple question-answering toward fully operationalized document-driven workflows, supported by accurate data, transparent logic, and intuitive interfaces.
In this evolving landscape, the combination of Databricks’ platform capabilities and SoftServe’s implementation expertise offers a compelling path forward, enabling businesses to turn their document repositories into a true source of actionable intelligence.
Let's build your document intelligence solution