

Gone are the days when artificial intelligence (AI) was a novel technology or a hyped trend. Now, AI solutions aid decision-making in nearly any process or workflow.
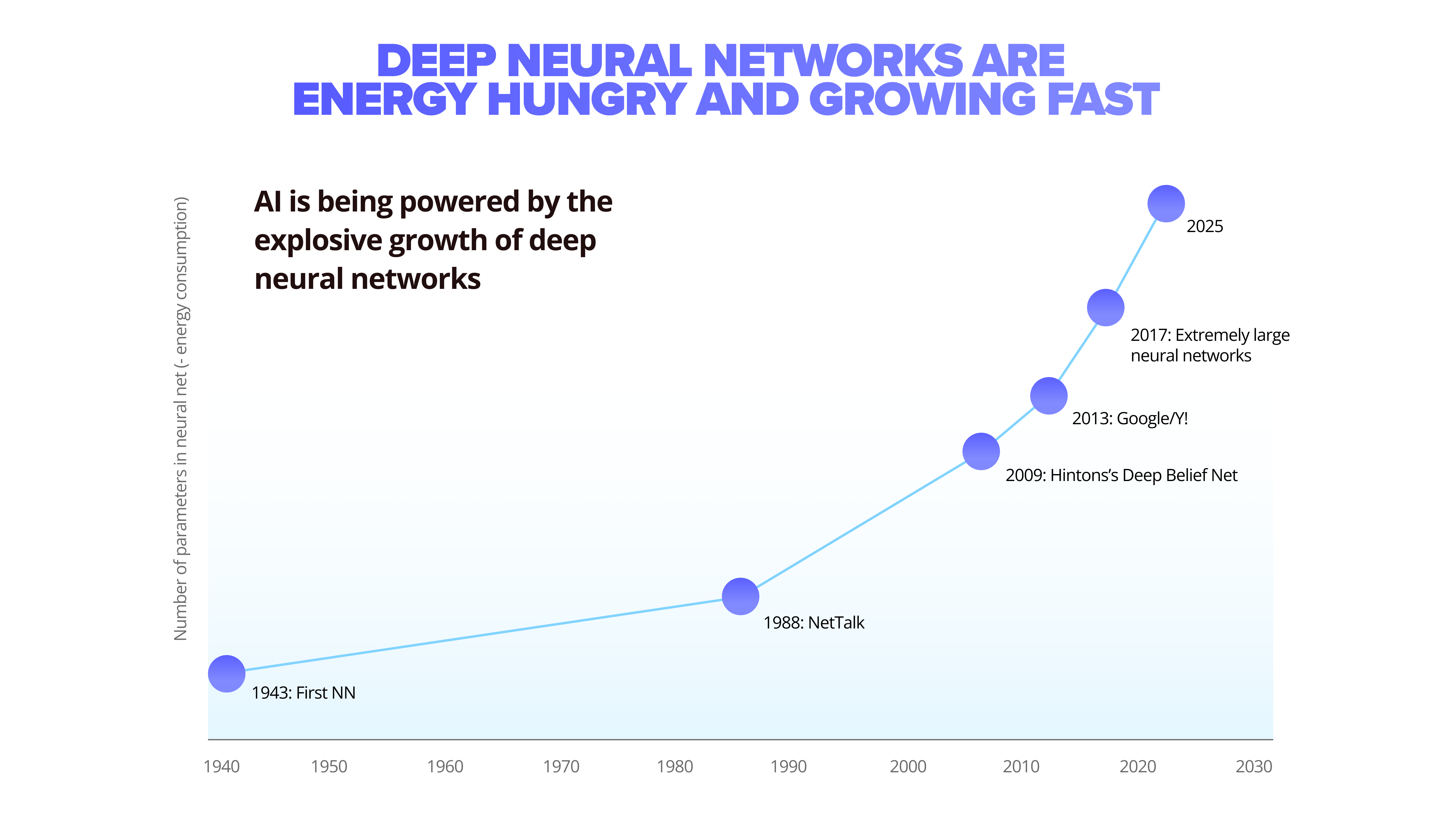
AI can scan the output of a production line and identify defects with edge devices. It can aggregate and build triggers using sensors and environmental data. It can process medical images from an MRI, X-ray, or CT scanners to automatically identify illnesses or injuries. AI is a capable computing tool, but that capability comes with increasing cost, hardware, and power requirements. This creates a three-part problem that complicates AI development resource-wise.
Computational demands
First, computational demands for deep neural networks have become exponentially more resource-expensive to train and compute. For example, the latest Megatron-Turing NLG algorithm is the largest monolithic transformer language model trained by Microsoft’s R&D, containing 530 billion parameters.
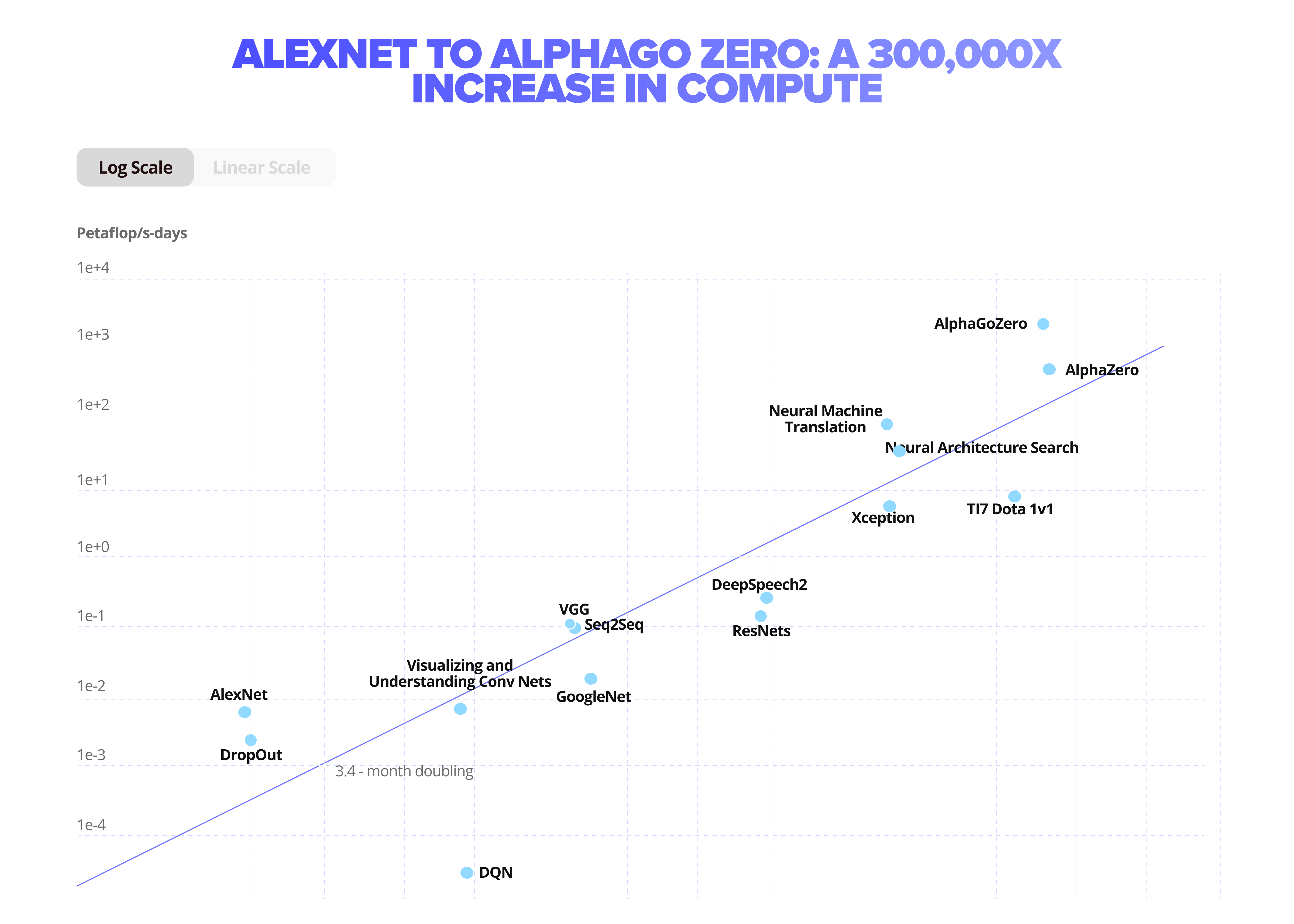
Stacking of transistors
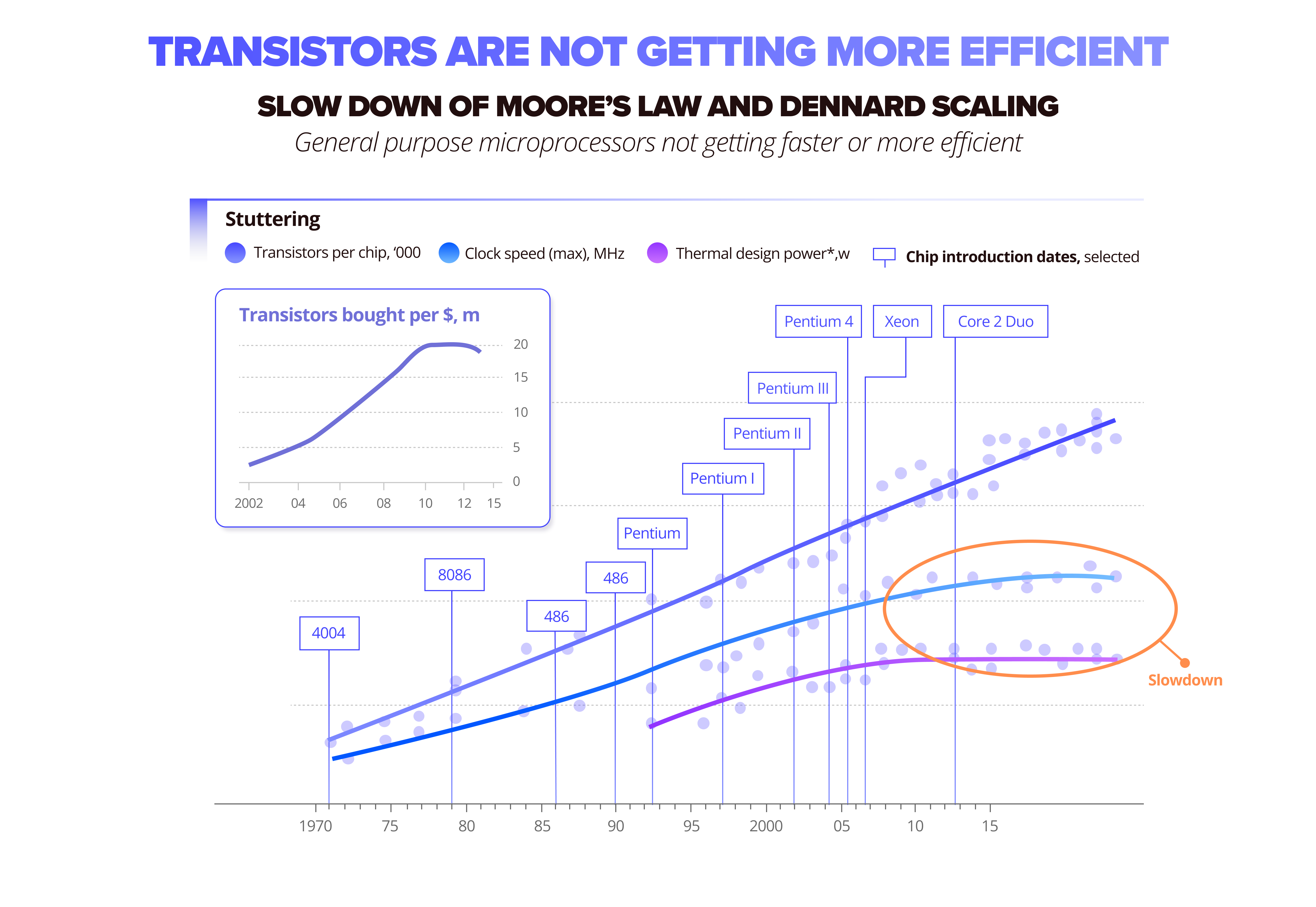
The second issue is the stacking of transistors and their decrease in physical size (such as with the latest 2-3nm models) has almost reached the point where the computational returns are quite negligible.
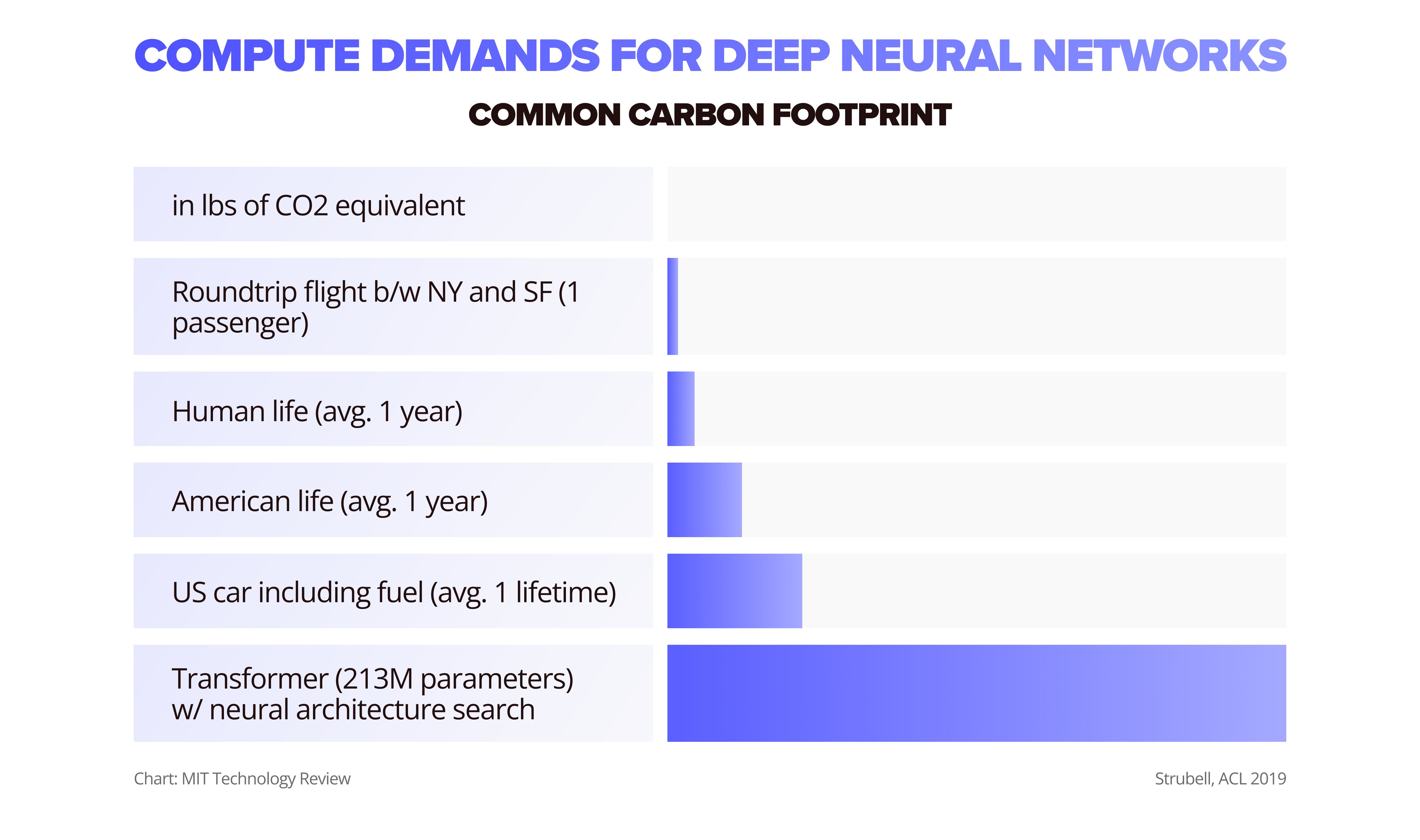
Power consumption, thermals, and carbon footprint
The third issue is power consumption, thermals, and carbon footprint. Because of complex computations, current AI model transformers consume more power and produce 313 times more CO2 equivalent than a roundtrip flight between New York and San Francisco, according to MIT Technology Review.
How can we find the balance between power consumption and performance? Next, we’ll examine how you can create an economically superior and optimized AI for edge and mobile.
Hardware(,) less(,) software. Choose where the comma goes.
We’ve already reached the threshold of Moore’s law, where stacking hardware and minimizing the size of a chip is no longer an ultimate solution. Instead, we would rather perfect how software is built, designed, and executed on specific devices or deployed in a hardware line.
To solve this problem, we developed our own “Efficient AI” approach. Instead of using more computational power, we reengineered and designed more efficient AI algorithms that were faster and less memory and computationally expensive, while retaining the same algorithm accuracy. This approach creates new possibilities for using AI on edge devices with limited resources, which allows clients to significantly reduce cloud costs. We also created new business use cases for AI that were not accessible before because of the models’ slowness and size.
Core challenges in running AI
Designing a well-rounded AI algorithm is a challenge itself. Having project restraints and business requirements is less of a problem, as you inevitably encounter a dilemma on how to balance your AI system between the following parameters:
- Power: An unoptimized AI run on scale (such as in data centers) tends to consume higher amount of energy, which eventually leads to the following problem.
- Environmental harm: A larger carbon footprint from higher energy consumption levels increases the impact on our environment. The larger the scale of AI run, the bigger the impact.
- Speed: Another dilemma faced while designing AI architecture is where it’s being run, either in the cloud or locally on a device. Both options lead to speed constraints.
- Size: Unoptimized models are heavy and unusable on the edge/models.
- Amount of training data needed: AI requires large and detailed sets of data to train data-hungry models. Instead of engineering quality architecture of models, it’s common to stack more hardware to run less optimized models with the same performance.
- Democratization of devices: AI models tend to become heavy and resource-demanding, eventually restricting the ability to run them on small devices.
- Training times: Developing an optimized AI model, which is also being trained in enough time, is another parameter that must be optimized for an efficient AI workflow.
What is efficient AI?
Efficient AI is a field of computer science and artificial intelligence that focuses on developing energy-efficient and high-performance AI systems to enable optimal balance between power, speed, dataset size, required memory, and quality results.
Instead of using more computers, we create better AI algorithms that are faster, use less memory and are computationally expensive, but have almost the same accuracy. That opens new possibilities for using AI on edge devices with limited resources, allowing a significant reduction of cloud cost and creating new use cases for AI in business which were not accessible before.
Device-specific vs hardware-independent approach
-
Hardware-independent optimization focuses on researching and developing efficient AI model design and data processing pipelines that are applicable on any platform it could be running on. It includes NN model compression and optimization features such as Knowledge Distillation, Weight Sharing, Pruning, Quantization, and Binarization (read more).
We also pay close attention to those innovative ML model architecture design and approaches that allow for the solving specific AI problems more efficiently in terms of energy, storage, or required training data (such as Meta-learning), including:
- NN model compression and optimization features
- AutoML for the rapid design of optimized NN architectures
- Design of innovative, efficient AI system architecture, and approaches to solve specific tasks
-
Hardware-specific optimization focuses on developing efficient, low-level data processing algorithms and system architecture design to get the best performance on the specific device. Hardware has different memory size, time of communication, number of operations per second, and other factors, so the algorithms should be optimized to these specific requirements.
Developing efficient AI models is important, but the most significant energy consumption comes not only from the model computations themselves but from the low-level data movement and processing. That is why our second area of focus is on the optimization of data processing that is tailored to specific hardware, which allows us to get the best performance and desirable results considering distinct differences and features of the hardware.
It includes the development of:
- Low-level optimization and development of high-performing custom AI frameworks and libraries (C/C++, CUDA).
- Parallelization of AI systems based on the hardware constraints
- Use of the state-of-the-art frameworks (e.g., TensorRT, Metal) and approaches for deployment and optimization depending on hardware (GPU, CPU, FPGA, and mobile devices)
We previously discussed how to optimize and efficiently compress deep learning AI models.
Benefits of efficient AI
AI software optimization enables reaching the optimal balance between five key parameters: Energy efficiency, algorithm speed, model size, training dataset size, and performance quality. Optimizing AI algorithms on devices brings many benefits that simplify workflow in a variety of business cases.
Efficient AI provides:
- Enabled edge AI: Lower power consumption allows moving AI processing to the edge of the device and reduces communication requirements, which preserves data processing privacy, provides low latency, and offers the potential for scalability.
- AI parallelization: Accelerating AI systems by parallelizing computations allows clients to achieve a fast system response and to open new AI business use cases
- Significant power consumption reduction: Reducing power needed for the same performance saves costs for the cloud and computation resources and reduces the carbon footprint from running AI algorithms.
- Data efficient AI: Reducing needs on data collection and extensive dataset preparation makes Efficient AI systems more adaptive and cost efficient.
Now let’s see what technological trends and solutions in the market are that enable us to optimize and increase performance of AI while keeping power consumption and other parameters balanced.

Efficient AI Trends
Tiny ML
Tiny ML (machine learning) is a rapidly expanding field of ML technologies and applications that includes algorithms, hardware (dedicated integrated circuits), and software that can perform on-device sensor (including vision, audio, IMU, and biomedical) data analytics at extremely low power, typically in the mW range and below. It supports a wide range of always-on scenarios and focuses on battery-powered devices.
Tiny ML has already shown tremendous promise and is poised to become the largest section of the edge machine learning (ML) industry in terms of shipping volume. According to ABI Research, Tiny ML chipsets will be used in 1.2 billion devices in 2022. Furthermore, as ultra-low-power ML applications become more common, more brownfield devices will be outfitted with ML models for anomaly detection, condition monitoring, and predictive maintenance on-device.
IoT AI
It becomes easier to create machines as they become smaller. Recently, there has been a movement in the technology mindset, as industries move away from monolithic, single-device models toward a more modular, microservices-based strategy. Instead of relying on a single device to do all calculations and measurements, a network of devices may do so. Each device may have its own unique utility, which may be beneficial to the entire network. The Internet of Things (IoT) technology is built on this concept.
According to Mordor Intelligence, the IoT technology market value is expected to reach $1.39 trillion by 2026.
Supporting artificial intelligence software is one of the most intriguing applications of IoT technology. Artificial intelligence and the Internet of Things have a symbiotic connection. IoT benefits AI with dispersed data, while AI benefits IoT with better management.
Efficient AI R&D
SoftServe’s R&D is a team of more than 100 cross-disciplinary Ph.D.-level researchers, engineers, software developers, and product managers building innovative solutions with the latest tech advancements. Mid-air tactile digital textures and contactless vital signs measurement with a camera, to ultra-precise 3D scanning and quantum computing, are but a tiny part of what we work on besides Efficient AI.

Through the years we have worked on many commercial projects and non-profit initiatives, prototyping, and building products for industries.
Our recent projects include:
- Neural networks optimization on GPU: We took a Tensorflow model that runs on GPU and made it 10x faster without any significant accuracy loss. This allows users to accelerate the defect detection AI pipeline and increase production line capacity.
- INDUSTRY 4.0 Automated visual inspection: SoftServe developed an optimized computer vision system that captures any product defects on the manufacturing line. It works on the edge device in real-time and is adapted for a high-load environment.
- Multi-GPU hyperparameter optimization research: We developed a universal method for efficient parallel multi-GPU ML model optimization.
- Binary Neural Network for Tiny ML: SoftServe researched an innovative way to train very small neural networks which opens new opportunities for AI on low-power hardware. We evaluated direct training of binarized networks without using SGD or float representations in between.
- Computer Vision optimization on CPU: SoftServe optimized the performance Computer Vision tasks on C++.
We help companies regardless of their technological maturity stage. From scratch prototyping to optimizing existing algorithms, to a given workflow and infrastructure—we’re present on every step of value chain, achieving operational excellence in enterprises with an efficient and resource-light AI. If you’re thinking of building a balanced and economical AI workflows for your enterprise, we’d love to chat.
About SoftServe
SoftServe is a digital authority that advises and provides at the cutting-edge of technology. We reveal, transform, accelerate, and optimize the way enterprises and software companies do business. With expertise across healthcare, retail, energy, financial services, and manufacturing, we implement end-to-end solutions to deliver the innovation, quality, and speed that our clients’ clients expect.