

Lakebase Makes the Lakehouse Operational: Real-Time Apps and Agents Without a Second Database

In brief:
- Operational apps and agents still rely on a separate database and Kafka cluster alongside the Lakehouse, adding governance overhead and integration complexity.
- Lakebase provides managed Postgres — tightly integrated with Delta and Unity Catalog — for both millisecond reads and agent read-write state.
- Zerobus delivers serverless gRPC ingest directly to Bronze Delta, removing the need for a Kafka cluster for row-level producers.
The Lakehouse Won Analytics. Operational Apps Still Did Not.
The Lakehouse pattern won the analytics conversation. Adoption is broad, the medallion shape is well understood, and most enterprises we work with already have their analytics workloads on it. What still lives somewhere else, more often than not, are the operational applications: interactive UIs that need fresh data in milliseconds, agents that read state and write it back, and real-time decisioning loops that drive procurement, fulfillment, maintenance, or pricing.
The pattern those teams use is familiar. A pipeline pulls data from Delta into a separate Postgres, Mongo, or Redis instance. The application reads from that second database. Sometimes a reverse-ETL job pushes writes back into Delta on a schedule. This is acceptable for a batch-flavored product. It hurts as soon as freshness needs to be measured in seconds, and agents start writing the state back.
For ingestion, the picture is similar. Auto Loader covers files arriving in cloud storage, which is the right tool for that shape, but it is the wrong tool when the producer is a PLC on a factory floor, an IoT bridge in a greenhouse, or a server-side process that wants to write rows directly. Teams put Kafka in front, write a custom socket bridge, or accept the latency of staging files in S3. Each option costs a piece of the platform story.
Where the Seams Show Up
The friction points are familiar to anyone who has tried to push a Lakehouse-fed app into production:
These are not minor issues. They are the reason many operational Lakehouse projects take far longer than the analytics work that started them, and why some never make it past the staging environment at all.
What Changed: Lakebase, Zerobus, and a Much Smaller Stack
Databricks now ships the parts that used to require a separate database next to the Lakehouse. Two of those parts, Lakebase and Zerobus, are the focus of this piece because together they remove the two pieces of glue that operational projects spent the most time on.
Lakebase is a managed Postgres, tightly integrated with Delta and governed by Unity Catalog. Two patterns matter. Synced tables are read-only Postgres views over Gold materialized views in Delta. They refresh every 30–60 seconds and serve queries with single-digit millisecond latency. Application-state tables are full read-write Postgres, intended for the things Delta is not designed to hold: agent inboxes, draft messages, queues, ledgers, audit logs, and anything that needs ACID semantics on a per-row basis. The two patterns sit in the same database, under the same access model, accessed through standard Postgres clients with OAuth-backed credentials.
Zerobus is a serverless gRPC ingest, direct to Bronze Delta. Producers, whether they are PLCs, IoT bridges, server-side processes, simulators, or CDC tools, open a gRPC stream over TLS and write rows. Writes are durable at millisecond latency. There is no Kafka cluster, no connector layer, no broker fleet, no client library to fork. Auto Loader is still the right answer for files arriving in cloud storage. Zerobus is the right answer when the source is a server speaking rows.
Each individual piece is a useful product. The point is that they finally compose without a custom integration project in the middle.
A Reference Architecture
The architecture below is the shape we propose to customers building real-time, agent-aware applications on the Lakehouse. It underpins the seven-minute vertical-farm procurement walkthrough we discuss further down, and it generalizes well to other operational use cases.
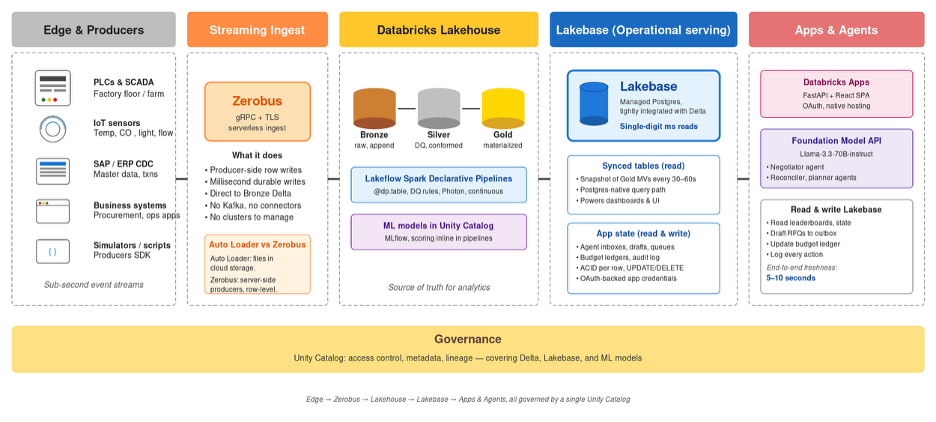
The Data Path, Layer by Layer
Edge & Producers. On the left of the picture are the components that generate events: factory PLCs, IoT sensors, SAP or ERP CDC streams, business systems, and the simulators that stand in for them during build-out. They emit sub-second event streams that need to land in the Lakehouse durably and quickly.
Streaming Ingest. Zerobus accepts those streams over gRPC and TLS. Each row is acknowledged with a millisecond latency budget and lands in a Bronze Delta table. Producers do not need to know about Kafka, partitions, or rebalancing. They just open a stream and write.
Databricks Lakehouse. Lakeflow Spark Declarative Pipelines move rows from Bronze through Silver to Gold. Pipelines are written in declarative PySpark with @dp.table functions and data-quality rules; Photon runs them continuously. ML models registered in Unity Catalog score in the pipeline itself, so by the time a row reaches Gold, it already has the predictions the application needs.
Lakebase. Gold materialized views snapshot into Lakebase-synced tables every 30–60 seconds. The application code reads them via a standard Postgres connection and gets single-digit millisecond response times. Alongside the synced tables sit application-state tables for everything Delta cannot serve well: per-row updates, writable queues, ledgers, and agent state. Both patterns are inside the same Postgres database, governed by the same Unity Catalog rules as the underlying Delta tables.
Apps & Agents. Databricks Apps host the UI as FastAPI plus a React SPA, with OAuth handled by the platform. Foundation Model API agents, often Llama-3.3-70B-instruct or similar, read context from Lakebase, decide on actions, and write the results back to the same Lakebase: a draft email into an outbox table, a recommendation into a queue, a budget update into a ledger, a row into an audit log. Every action is observable because it is a Postgres write under Unity Catalog.
Governance. Unity Catalog runs underneath all of this. Access control, metadata, and lineage are the same for Delta, Lakebase-synced tables, Lakebase application state, and ML models. There is no second permissions model to maintain.
Concrete Case: Real-Time Procurement on a Vertical Farm
The shape above is easier to reason about against a real workload. The walkthrough we use is a vertical-farm seed procurement application: a Lakehouse-native Auto Procurement product where every number on the dashboard is real, computed by Databricks in the last few seconds from four simulated streams, with negotiation emails drafted by an LLM through the Foundation Model API.
On the producer side, four feeds run continuously: inventory movements in grams, supplier quotes, demand events in trays per hour, and commodity prices for grow inputs. They open gRPC streams to Zerobus and write rows. Bronze tables in Delta accept them at millisecond latency, with no Kafka in the path.
Lakeflow Spark Declarative Pipelines move the rows through Silver and Gold. Data-quality rules drop or quarantine bad rows. A scoring model registered in Unity Catalog joins each SKU with live quotes, one-hour planting demand, and twenty-four-hour grow-input trends, then produces a supplier ranking. Gold materialized views snapshot to Lakebase-synced tables every 30–60 seconds.
The application is a React SPA hosted as a Databricks App. It reads dashboards, supplier leaderboards, and procurement recommendations from the Lakebase synced tables in single-digit milliseconds, regardless of how heavy the underlying Delta workload is. End-to-end freshness, sensor to UI, lands in the five-to-ten-second range.
On top of that, two agents run. The negotiator agent reads the supplier leaderboard from Lakebase, drafts requests for quote against the recommended suppliers, and writes them to an email outbox table in Lakebase. The reconciler agent reads invoices, compares them to purchase orders, and flags variances in a separate review queue. A budget agent updates a Postgres ledger every time a draft moves to committed. None of these agents talks to a separate state store. Every read and every write is a Lakebase row, every action ends up in an audit log, and every step is governed.
The pre-Lakebase version of this application would have used three databases, a Kafka cluster, two role-based access control sets, and at least one reverse-ETL job to keep the operational store in sync with the analytical one. Most of that goes away. The team builds the application instead of the integration around it.
Why This Is More Than a Postgres Add-On
It is tempting to file Lakebase under "managed Postgres on Databricks" and move on. That would miss the architectural point. The serving layer for operational apps is no longer outside the Lakehouse. Synced tables keep the read side current with Gold. Application-state tables let agents write back without leaving the platform. One governance model covers both. One audit trail covers both. There is no second store to keep alive.
Zerobus is the same kind of consolidation on the way in. Producers no longer need a Kafka middleman to land rows in Bronze with durability and millisecond latency. The operational cost of running an ingest cluster falls off the table.
The reduction in moving parts is the headline. Postgres compatibility is what makes it cheap to adopt without rewriting the application; the architectural simplification is what makes it worth adopting at all.
Where to Start
A useful first project is one where the separate operational database is already hurting you. The common shapes are procurement, fulfillment, predictive maintenance, dynamic pricing, fraud monitoring, and any agentic workflow that reads fresh Lakehouse data and writes state back. If the application needs single-digit millisecond reads on data that comes from the Lakehouse, and the agents need a real read-write store for their own work, the pattern fits.
Sequence the move in three steps. Move the read path first: replace reads against the separate database with a Lakebase synced table over the relevant Gold view. Then move the writable state: lift agent inboxes, queues, ledgers, and drafts into Lakebase application-state tables under the same Unity Catalog. Finally, take a look at the ingest side. If a Kafka topic exists solely to land producer rows in Bronze, Zerobus probably replaces it.
SoftServe runs focused engagements around this pattern, scoped to a first production-shaped slice rather than a full rebuild. The previous offerings we have written about, Genie Express and Document Intelligence with Genie, sit on the analytical side of the Lakehouse. This pattern is the operational counterpart, and in customers building real-time agent-aware products, it tends to be paired with one or both of them.
Conclusion
The Lakehouse story has been about consolidation since the start. The first wave consolidated the data warehouse and the data lake. Lakebase consolidates the operational serving layer. Zerobus consolidates the ingest path for row-level producers. Together, they collapse the rest of the operational stack into a single platform.
For the teams who have been quietly using Delta for things it wasn't built for, or running a separate Postgres because there was no other option, this is the path out. The math on rebuild versus continue is unusually clear: less infrastructure, fewer governance reviews, a single freshness story, and a sensor-to-UI loop measured in seconds rather than in batch cycles.
Let's simplify your operational Lakehouse stack